Andrew OzbuninNerd For TechColumn CleanlinessHow to Clean a Really Dirty Column5 min read·Jul 11, 2021----
Andrew OzbuninNerd For TechProperly Using SMOTETales of a Learning Experience3 min read·Jul 5, 2021--1--1
Andrew OzbuninGeek CultureCracking the CodeMaking the terrifying technical interview less terrifying.5 min read·Jun 27, 2021----
Andrew OzbunOrdinary Least Squares 2 WaysJust the phrase ‘Ordinary Least Squares’ used to give me so much anxiety. It sounds so official. If you can’t tell from my other blog posts…6 min read·Jun 17, 2021----
Andrew OzbuninGeek CultureWhat the Heck is Multicollinearity?The Who, Where, When, What, Why, & How of Multicollinearity.6 min read·Jun 9, 2021----
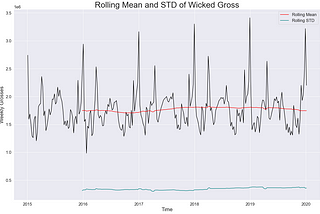
Andrew OzbuninCodeXUnit Root In Time SeriesIn data science we talk a lot about adding a narrative to something, usually in the context of data visualization. This is what I love…7 min read·May 24, 2021----
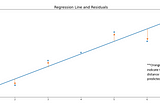
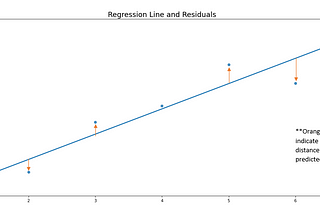
Andrew OzbunMeasuring Errors and What They Inference in Linear RegressionI just remember sitting in data science boot camp and it being drilled into our heads to check the Mean Squared Error (MSE), the Root Mean…6 min read·May 9, 2021----
Andrew OzbunCreating an Elegant PlotCreating visualizations for you data is essential. In another post I did I take an in depth look at EDA according to the National…8 min read·Apr 19, 2021----
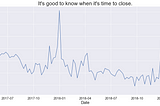
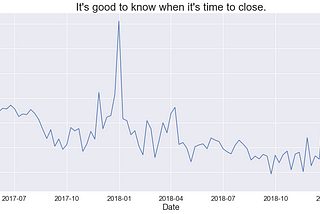
Andrew OzbunClass Imbalance and Hyperparameters in SVMIn a recent project on Broadway Grosses I used machine learning to predict when a Broadway show would close based on features like…5 min read·Apr 18, 2021----
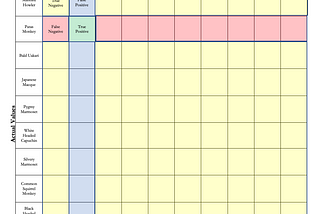
Andrew OzbuninCodeXUnderstanding large confusion matrices.The confusion matrix is a vital part of our work as data scientists. Our bread and butter; it is a form of visualizing the performance of…6 min read·Mar 25, 2021----